Unlocking Language: Demystifying BERT, Google's NLP Revolution
In the ever-evolving landscape of artificial intelligence, few innovations have reshaped our interaction with machines quite like BERT. Introduced in October 2018 by researchers at Google, BERT, which stands for Bidirectional Encoder Representations from Transformers, is not a person, but a groundbreaking language model that has profoundly impacted Natural Language Processing (NLP). It marked a significant leap forward in how computers understand and process human language, moving beyond traditional, often rigid, methods to grasp context with unprecedented accuracy.
Before BERT, language models often struggled with the nuances of words that change meaning based on their surrounding text. Imagine trying to understand a joke or a subtle hint without knowing the full conversation – that was the challenge for many AI systems. BERT changed this by learning to represent text as a sequence of interconnected meanings, allowing it to "read" and comprehend language in a way that mirrors human understanding more closely. This paradigm shift has opened doors to more intelligent search engines, more accurate translation tools, and a host of other applications that were once considered the realm of science fiction.
Table of Contents
- What Exactly is BERT? The Bidirectional Breakthrough
- The Genesis of a Giant: BERT's Introduction and Core Idea
- Under the Hood: Understanding BERT's Architecture
- The Training Ground: Unsupervised Learning Tasks
- Practical Powerhouse: Real-World Applications of BERT
- The BERT Family: A Legacy of Innovation
- Why BERT Matters: Its Enduring Impact on NLP
- Conclusion: The Future Shaped by BERT
What Exactly is BERT? The Bidirectional Breakthrough
At its core, BERT is a sophisticated language representation model. Its full name, Bidirectional Encoder Representations from Transformers, gives us crucial clues about its nature. "Bidirectional" is key here; unlike many previous models that processed text in a single direction (either left-to-right or right-to-left), BERT reads sentences both ways simultaneously. This unique approach allows it to grasp the full context of a word by considering the words that come before and after it, leading to a much richer and more accurate understanding of meaning. The "Encoder Representations" part refers to its ability to convert words and sentences into numerical vectors (representations) that computers can understand and process. These representations are not just simple word-to-number mappings; they encode deep contextual meaning. Finally, "Transformers" points to the neural network architecture it employs. The Transformer architecture, introduced by Google in 2017, was a breakthrough in itself, excelling at handling sequential data like text by allowing the model to weigh the importance of different words in a sentence when processing another word – a concept known as "attention." This combination of bidirectionality and the Transformer architecture is what makes BERT so powerful.The Genesis of a Giant: BERT's Introduction and Core Idea
The story of BERT began in October 2018, when researchers at Google unveiled this novel language model. Their aim was to create a pre-trained model that could be fine-tuned for a wide array of NLP tasks, significantly reducing the need for extensive task-specific training data. The main idea behind BERT was to pre-train a deep bidirectional representation from unlabeled text by jointly conditioning on both left and right context in all layers. This was a departure from previous models that were either unidirectional or shallowly bidirectional. The core innovation wasn't just in its architecture but in its training methodology. BERT was trained on a massive corpus of unlabeled text, allowing it to learn general language understanding without explicit human supervision for specific tasks. This unsupervised pre-training phase is what gives BERT its remarkable contextual power. By predicting masked tokens in a sentence and determining if one sentence logically follows another, BERT developed an internal representation of language that captures complex semantic and syntactic relationships.Beyond Unidirectional: How BERT Reads Language
To truly appreciate BERT's impact, it's essential to understand the "bidirectional" aspect. Consider the sentence: "The bank of the river was steep." And then, "I went to the bank to deposit money." In traditional unidirectional models, the word "bank" would be processed based only on the words preceding it, potentially leading to ambiguity. BERT, however, reads them both ways, making sense of context more effectively. It understands that "bank" in the first sentence refers to a geographical feature, while in the second, it refers to a financial institution, all thanks to its ability to look at the words on both sides. This simultaneous processing of left and right context is what allows BERT to achieve such a nuanced understanding of polysemous words (words with multiple meanings) and complex sentence structures. This fundamental shift in how language models process input text was a game-changer for contextual understanding.Under the Hood: Understanding BERT's Architecture
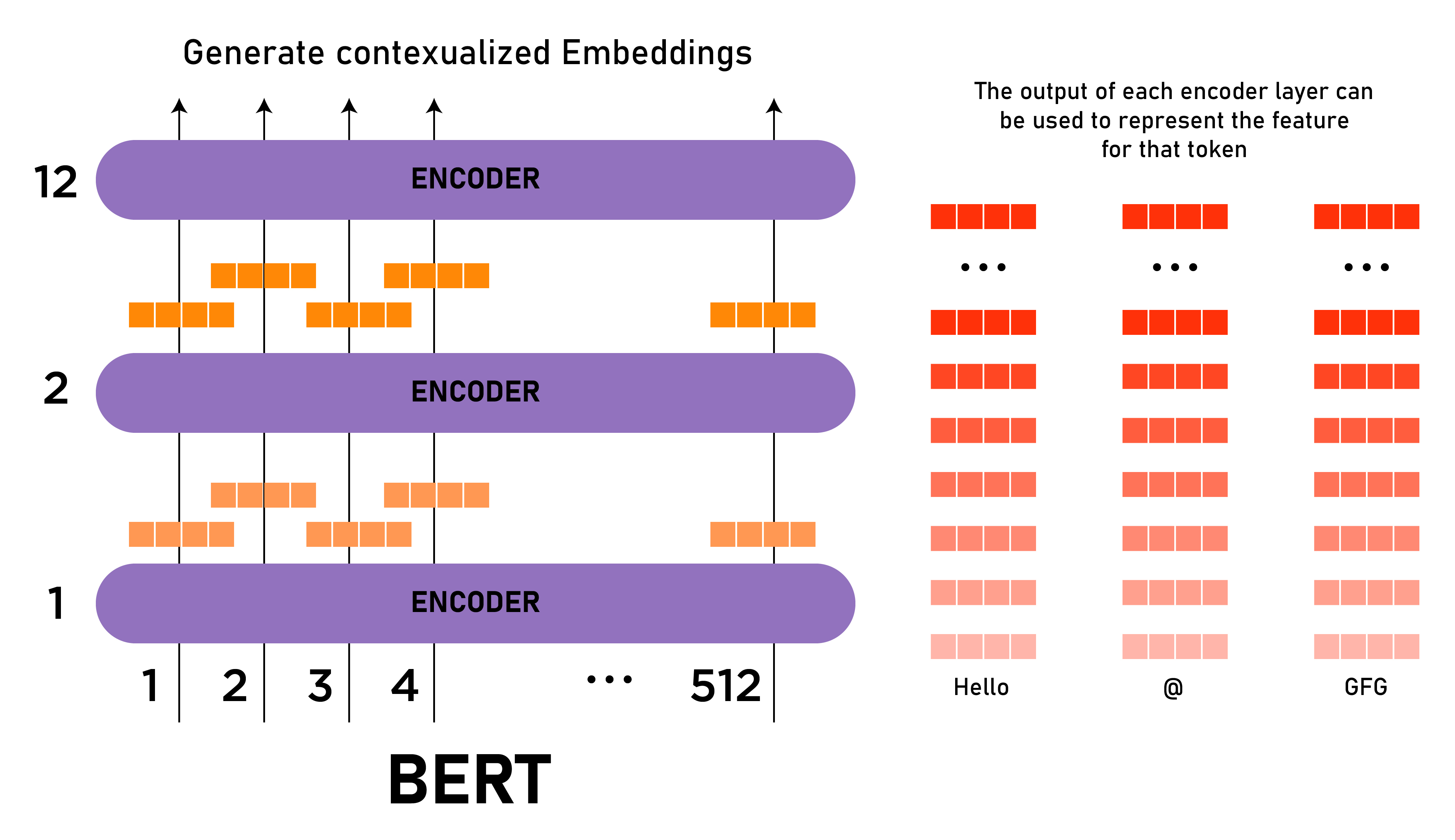
The internal structure of BERT is a marvel of modern deep learning. While the full architecture can be quite complex, understanding its key components helps demystify its capabilities. BERT is built upon the Transformer architecture, which eschews traditional recurrent or convolutional networks in favor of attention mechanisms. These mechanisms allow the model to weigh the importance of different words in a sentence when processing another word, regardless of their distance from each other. There are different versions of BERT, but the most commonly discussed are BERT Base and BERT Large. BERT Base, for instance, consists of 12 transformer layers, while BERT Large boasts 24 transformer layers. Each layer is equipped with sophisticated mechanisms to process input and output text effectively. The scale of these models is impressive: BERT Large features 1024 hidden units and 16 attention heads, culminating in a staggering 340 million parameters. For most text classification tasks, BERT Base provides an excellent balance of performance and computational efficiency, making it a popular choice for developers. The sheer number of parameters allows BERT to learn incredibly intricate patterns and relationships within language, making it highly adaptable to various NLP challenges.Layers, Units, and Attention: The Power of Transformers
Let's break down the components mentioned: * **Transformer Layers:** These are the core processing blocks of BERT. Each layer refines the understanding of the input text, passing its enhanced representation to the next layer. The more layers, the deeper the model's ability to extract complex features. * **Hidden Units:** These refer to the dimensionality of the internal representations within the network. A larger number of hidden units allows the model to capture more information and nuances about the language. * **Attention Heads:** The multi-head attention mechanism is a key innovation of the Transformer. Instead of focusing on just one aspect of the relationship between words, multiple "attention heads" allow the model to simultaneously focus on different aspects of the input. For example, one head might focus on syntactic relationships (like verb-noun agreement), while another focuses on semantic relationships (like synonyms or antonyms). This parallel processing of different contextual relationships significantly enhances BERT's ability to understand complex sentences. The 16 attention heads in BERT Large mean it can process 16 different aspects of word relationships concurrently, leading to a comprehensive understanding.The Training Ground: Unsupervised Learning Tasks
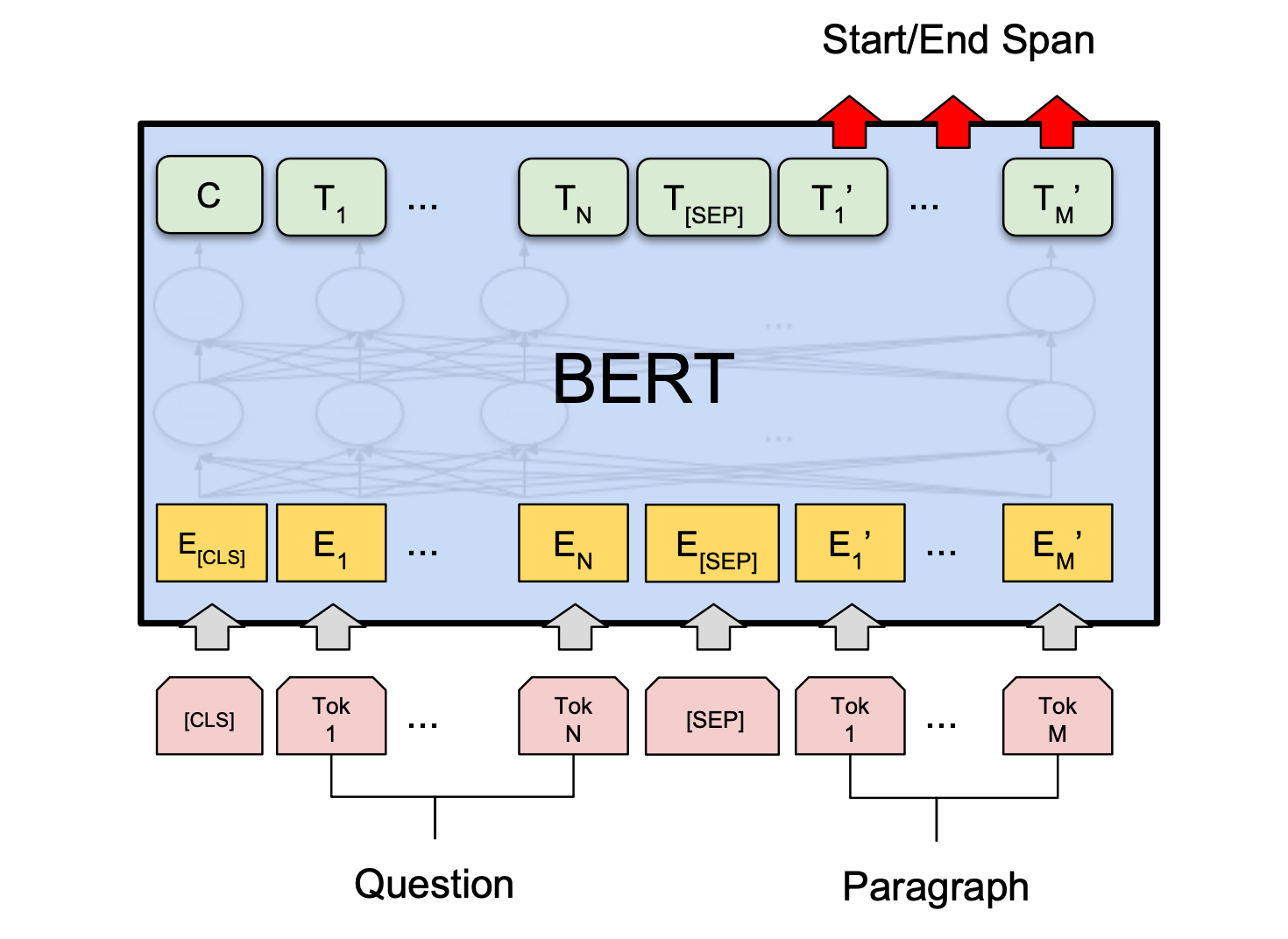
BERT's remarkable contextual power stems from its training methodology, which involved two novel unsupervised tasks. "Unsupervised" means the model learned from raw text without requiring human-labeled examples for specific tasks, making it incredibly scalable. 1. **Masked Language Model (MLM):** In this task, a certain percentage (typically 15%) of the words in a sentence are randomly "masked" or hidden. BERT's goal is then to predict these masked words based on the context provided by the unmasked words around them. Because it processes text bidirectionally, it can use information from both sides of the masked word, which is crucial for accurate prediction. This forces the model to develop a deep understanding of word relationships and context. 2. **Next Sentence Prediction (NSP):** This task helps BERT understand the relationship between two sentences. The model is given two sentences (Sentence A and Sentence B) and must predict whether Sentence B logically follows Sentence A in the original document. This is vital for tasks like question answering and document summarization, where understanding inter-sentence coherence is paramount. By mastering these two pre-training tasks on vast amounts of text data (like the entire English Wikipedia and BookCorpus), BERT develops a robust internal representation of language that can then be fine-tuned for a multitude of downstream NLP applications with relatively little task-specific data. This pre-training approach is a cornerstone of modern transfer learning in NLP.Practical Powerhouse: Real-World Applications of BERT
The advent of BERT has significantly enhanced the performance of numerous Natural Language Processing applications. Its ability to understand context deeply has made it an indispensable tool across various industries. From sentiment analysis to spam detection, document classification, and question answering systems, BERT has consistently pushed the boundaries of what's possible. Here are some key areas where BERT has made a substantial impact: * **Search Engines:** Google itself integrated BERT into its search algorithm, dramatically improving its ability to understand complex queries and provide more relevant results, especially for longer, conversational searches. * **Question Answering Systems:** BERT excels at reading a passage of text and answering questions about it, often by identifying the exact span of text that contains the answer. This is crucial for chatbots, virtual assistants, and knowledge retrieval systems. * **Sentiment Analysis:** Understanding the emotional tone behind text – whether it's positive, negative, or neutral – is vital for customer service, market research, and social media monitoring. BERT's contextual understanding allows for highly accurate sentiment detection. * **Text Classification:** This includes tasks like spam detection, categorizing news articles, or routing customer inquiries. BERT's robust representations make it highly effective at classifying text into predefined categories. * **Machine Translation:** While not a direct translation model, BERT's contextual embeddings can be used as a component in larger translation systems to improve the quality of cross-lingual understanding. * **Text Summarization:** By understanding the core ideas and relationships within a document, BERT-based models can generate coherent and concise summaries. * **Chatbots and Conversational AI:** BERT helps these systems understand user intent and context, leading to more natural and effective conversations. The versatility and effectiveness of BERT mean that anyone in the field of NLP, from researchers to practical developers, now has a powerful tool at their disposal to tackle complex language challenges.The BERT Family: A Legacy of Innovation
BERT is not just a standalone model; it is the basis for an entire family of subsequent language models. Its success inspired a wave of research and development, leading to numerous variations and extensions that build upon its foundational principles. Models like RoBERTa, ALBERT, DistilBERT, XLNet, and ELECTRA are all part of the "BERT family," each introducing optimizations or new training strategies to improve performance, efficiency, or address specific challenges. For example, DistilBERT is a smaller, faster version of BERT that retains much of its performance, making it suitable for deployment on devices with limited computational resources. RoBERTa optimized BERT's training process, achieving even better results on several benchmarks. This continuous innovation demonstrates the enduring influence of BERT's original design and its role as a benchmark and starting point for advanced NLP research. The collaborative and iterative nature of AI development means that BERT's legacy continues to grow, with new models constantly emerging that owe a debt to its pioneering architecture and training methodology.Why BERT Matters: Its Enduring Impact on NLP
BERT (Bidirectional Encoder Representations from Transformers) is a groundbreaking model in natural language processing (NLP) that has significantly enhanced our ability to build intelligent systems. Its introduction marked a pivotal moment, shifting the paradigm from task-specific models to powerful, pre-trained general-purpose language understanding systems. Before BERT, achieving high performance on various NLP tasks often required extensive feature engineering and domain-specific knowledge. BERT democratized access to state-of-the-art NLP by providing a powerful, off-the-shelf model that could be fine-tuned with relatively little data. Its impact extends beyond academic benchmarks. By allowing machines to understand the nuances of human language with greater accuracy, BERT has paved the way for more intuitive and effective human-computer interaction. From improving the accuracy of search results to enabling more natural conversations with AI assistants, BERT has quietly become an integral part of our digital lives. It has made NLP more accessible to a wider range of developers and researchers, fostering innovation and accelerating progress in the field. The principles introduced by BERT – bidirectional context, the Transformer architecture, and unsupervised pre-training – have become foundational elements of modern NLP, influencing nearly every subsequent advancement in the domain.Conclusion: The Future Shaped by BERT
In summary, BERT represents a monumental leap forward in Natural Language Processing. Introduced by Google in October 2018, this bidirectional transformer model revolutionized how machines understand human language by considering context from both directions. Its pre-training on masked language modeling and next sentence prediction tasks allowed it to develop a deep, contextual understanding of words and sentences, a capability that was previously elusive for AI. From powering more intelligent search queries to enhancing sentiment analysis, spam detection, and question-answering systems, BERT's practical applications are vast and continue to grow. It laid the groundwork for an entire family of advanced language models, solidifying its place as a cornerstone of modern AI. The principles and techniques pioneered by BERT continue to shape the direction of NLP research and development, promising even more sophisticated and human-like language understanding capabilities in the future. We encourage you to explore the fascinating world of NLP and see how models like BERT are transforming the way we interact with technology. Have you experienced the impact of BERT in your daily life, perhaps through a more accurate search result or a more helpful chatbot? Share your thoughts and experiences in the comments below, or delve deeper into our other articles on artificial intelligence and machine learning to continue your learning journey!
Bert Through the Years - Muppet Wiki
Explanation of BERT Model - NLP - GeeksforGeeks
An Introduction to BERT And How To Use It | BERT_Sentiment_Analysis
